Introducing VIDAS
We have spent more than five years developing AI and software that sees the world the way that humans do: by combining our knowledge and understanding of the world with direct measurements from parallax. We call our technology VIDAS: Visual Inertial Distributed Aperture System.

Depth
VIDAS delivers tens of millions of depth measurements per second without LiDAR or radar.

Scene Understanding
VIDAS identifies every object in the scene at the same time as measuring depth, improving performance on both tasks.

Position
VIDAS uses what it knows about the 3D structure of the world to track its own position as the system moves, without the help of GPS.
How It Works
VIDAS fuses information from three different sources of depth information: semantic cues from each frame, and parallax cues from both the motion of the cameras and the differences between the cameras.


Binocular Parallax
Given two images of a scene taken at the same time from different cameras, VIDAS can triangulate the distance to every point in the scene. We do not need to "understand" what we see; we can measure distance directly.
Motion Parallax
VIDAS can also measure distance by comparing two consecutive images from a single camera, provided it is moving. This is the most accurate way to measure distance with a single camera. Given two cameras, VIDAS combines binocular and motion parallax for increased accuracy.



Semantic Cues
People can often figure out the geometry of a scene from a single image. Nearby objects appear larger; parallel lines converge as they recede towards the horizon; objects further up the frame are farther away. VIDAS uses AI to understand the scene and combines this information with parallax cues.
Demo Gallery
See Our Technology In Action
Compound Eye's VIDAS technology leverages automotive-grade cameras and an embedded computer to perform tasks like depth measurement, scene understanding, and positioning in real time.

Ready to get started?
Build custom automotive applications with industry-leading perception software using our VIDAS Development Kit.
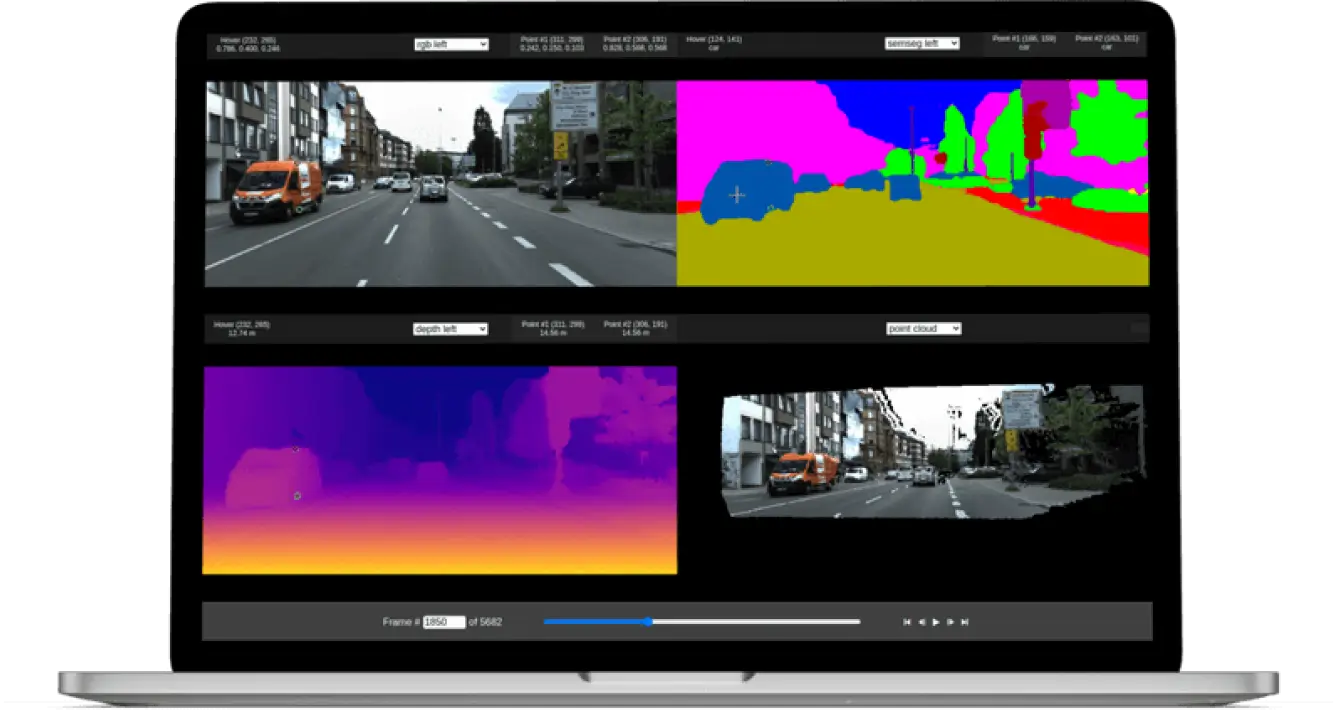
The VIDAS DevKit provides dense depth, per-pixel classification, and 6 DoF odometry in real time, enabling developers to build applications from enhanced situational awareness for vehicles to fully autonomous robots.
The VIDAS DevKit includes two cameras, two FAKRA cables, an optional GPS antenna, and a compute module, plus browser-based tools for data collection, inspection, and analysis, and an SDK for building applications on top of VIDAS.
The system is powered by 12VDC and draws approximately 30W during data collection.