

Building a Visual System for Machines
7/21/21
Article
Welcome to Compound Eye. We're building a visual system for machines: a combination of cameras, computers, and software that enable machines to perceive the world around them.
Everything that moves - dogs, cats, people, or robots - must understand the world in 3D in order to move through it. There are approximately two million species of animal on Earth and nearly all rely upon vision for motion planning. Flies, scallops, and sparrows have relatively small brains, no high tech, and seem to get around fine. Still — teaching machines how to see the world like we do is a difficult task.
See us in real-time
Our online demos show the real-time performance of our vision system. These seemingly normal videos are actually point clouds, true 3D representations of the world in front of the vehicle. You can explore the point cloud by changing the perspective and measure the distance to any point in the scene by using the ruler tool in the bottom left. Contact us to see live streaming demos from our test vehicles.
How it Works
Our visual system uses standard automotive-grade image sensors. The software runs on an embedded GPU, delivering ten times the resolution and range of most active sensors while consuming less power. Our goal is to build a fully redundant perception system for autonomous vehicles and other robots using only cameras, and that means measuring depth independently of other sensors.
Our goal is to build a fully redundant perception system for autonomous vehicles and other robots using only cameras, and that means measuring depth independently of other sensors.
There are two main ways that humans and other animals perceive the world in 3D: semantic cues and parallax cues. Compound Eye uses both.
Semantic Cues
You can reason about distance from a single image - or by standing still and looking at the world with only one eye open - because you have prior knowledge about the world. For example:
- You know the true size of cars and cats so you can tell out how far away they are from their apparent size in the image.
- You know the ground is usually flat and recedes towards the horizon and that can tell you the distance to every object on the ground.
- One object that partly blocks your view of another must be closer to you.
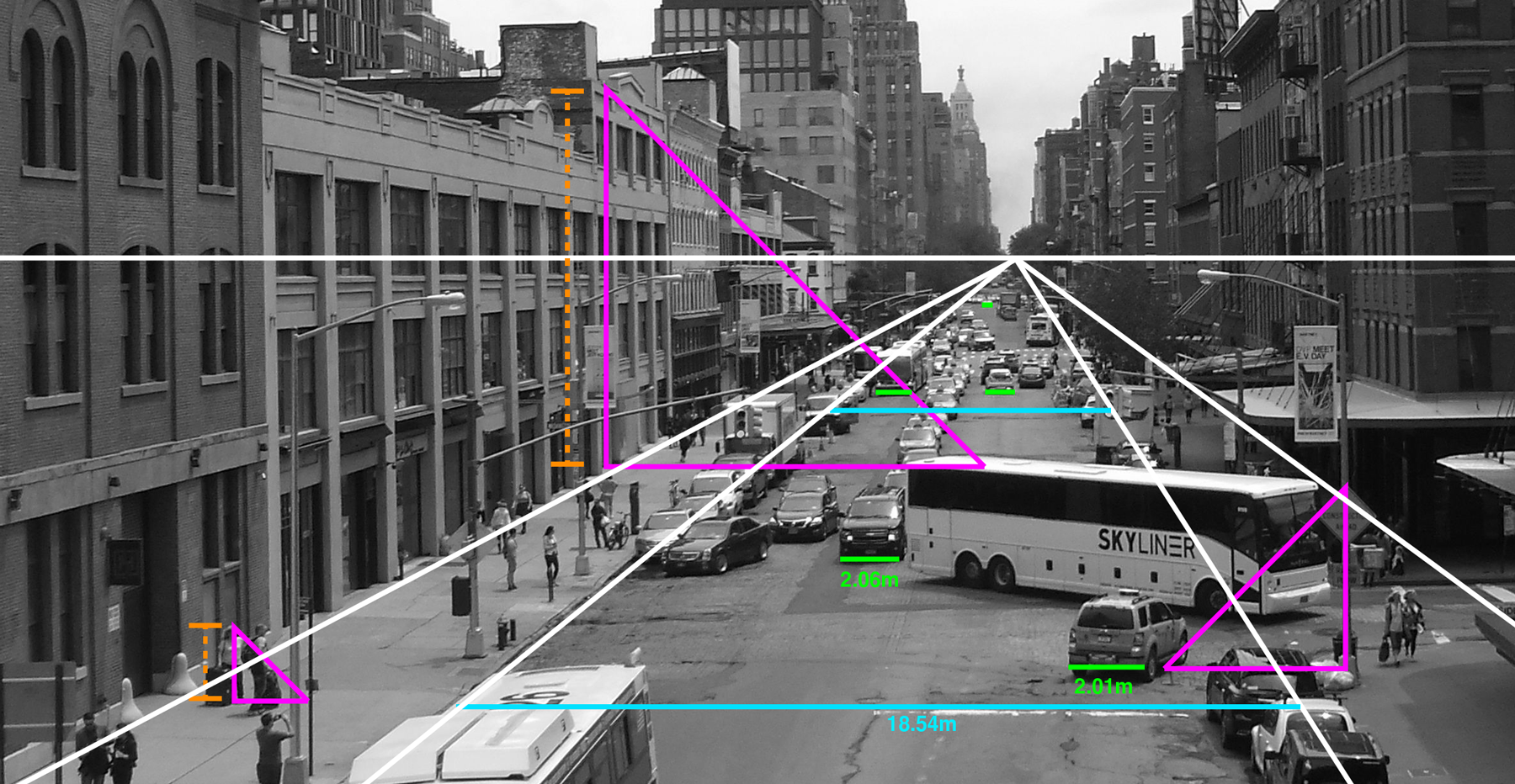
There are many other clues that people learn. Neural networks can also learn them given enough training data. But there are limits: Most things don’t come in standard sizes; sometimes the ground is not flat; unless you are looking at a line of cars or people, the objects in a picture are not all overlapping. In fact, it is mathematically impossible to figure out the geometry of most scenes from a single image or stationary video camera. Not just difficult - impossible. Fortunately, there is parallax.
Parallax Cues
Given two views of a scene from slightly different perspectives, you can calculate the distance to any point by triangulation. You don’t need to know anything else about what you are looking at; you just need to find the same point in each view.
One camera is enough, provided it is moving. Between images, nearby objects appear to move very quickly and those that are far away do not move at all. By keeping track of all the objects and motion, you can recover the exact geometry of the scene.

Neural networks can learn how to do this too, but there’s a limit. Think about a blank wall in a warehouse, a resurfaced road, or a clear sky - every point looks the same. Shiny cars can look quite different from different angles, which makes it hard to find the same point in two images. Some parts of the scene may only be visible in one image.
Compound Eye uses both semantic and parallax cues
Semantic and parallax cues provide different and complementary information. It’s not possible to find the exact same point in two images of a clear blue sky (parallax), but it’s easy to identify the sky and know that it is very far away (semantics). A car may look quite different in two different images (parallax), but it’s easy to recover the geometry of a car from one image (semantics). On the other hand, it’s hard to tell the difference between a person and a picture of a person given a single image, which is why some cars think they see pedestrians on billboards (semantics). But with two different views, it’s easy to tell that a billboard is flat (parallax). Given a single image, a neural network will assume the ground is flat (semantics), but given two it can measure the shape of the ground exactly (parallax).

Putting it all together
Our demo uses two forward-facing cameras. Compound Eye’s vision system fuses information from three different sources of depth information: semantic cues from each frame, and parallax cues from both the motion of the cameras and the differences between the cameras.
Most of the time we take human vision for granted, but 3D perception is complex and difficult to replicate. Compound Eye's team of researchers and scientists have spent five years developing a new framework for performing parallax-based depth measurement and monocular deep learning at the same time using off-the-shelf components. If you’d like to learn more, contact us. And if you’d like to work on these problems, join us!

